These notes are mostly based on the great survey article (Laurent, 2010).
This text and the code used to perform the experiments are hosted at gh:lcwllmr/momsos.
Read the instructions on GitHub if you would like to experiment with the code on your own.
Please feel free to contact me for questions, suggestions etc. at: luca dot wellmeier at uit dot no.
These notes have been used for the following talks:
Contents:
Let be the polynomial ring in variables with real coefficients. We start with the following lead problem: decide whether a given polynomial defines a globally non-negative function (in short, ). While we expect this to be very hard to solve in general, we may consider some special cases of polynomials.
Example (Univariate case): Let and assume that is non-negative. Necessarily, we must have that is even, and that the leading coefficient of is positive (we might as well take monic). We also note that any real root might have must appear with even multiplicity as otherwise flip sign there. Consider a factorization of into real roots and complex conjugate root pairs:
Thus, with , we obtain the expression .
We have proven that every non-negative univariate polynomial is a sum of squares of other polynomials. Of course the reverse, i.e. being a sum of squares, trivially implies non-negativity. Is it possible that non-negativity can be characterized by the sum-of-squares (or abbreviated, sos) criterion? Let's see another case.
Example (Quadratic case): We now let be arbitrary and pick such that and . We may write
where is a symmetric -matrix, be an -vector and a constant. First, observe that the non-negativity of implies that is positive semidefinite (or psd for brevity): indeed, if this were not the case, there would be a direction s.t. and thus as . Next, consider the homogenization of in vectorized form:
Note that since is psd and since whenever , so that globally on . It follows that its defining matrix is psd itself and we may consider a Cholesky factorization to find
This last expression for is again a sum of squares of affine functions.
As for the univariate case, it turns out that non-negativity and being a sos is equivalent in case of quadratic polynomials as well. This should provide enough motivation to introduce dedicated symbols.
Definition: The set of non-negative polynomials and the set of sos polynomials will be denoted respectively by and . Their respective truncations at degree are denoted by by and . The subscript may be dropped if the number of variables is clear from the context.
Both and are convex cones: they are closed under addition and multiplication by non-negative scalars and clearly . We have seen two families for which we even have equality - how far can we go with this? Not much further unfortunately - a result which motivated Problem 17 in Hilbert's 1900 list of 23 problems.
Theorem (Hilbert, 1888): The equality holds if and only if is either of , or .
In fact, the situation looks rather hopeless:
Theorem (Blekherman, 2006): Fix an even degree and let be the compact set of all such that . Then, as
The paper gives exact asymptotic rates (think ; very fast), but the point is clear: the density of in is vanishingly small in many variables or high degree. Nonetheless, sos-based methods have proven very practical for a wide variety of applications. The next section will justify this claim.
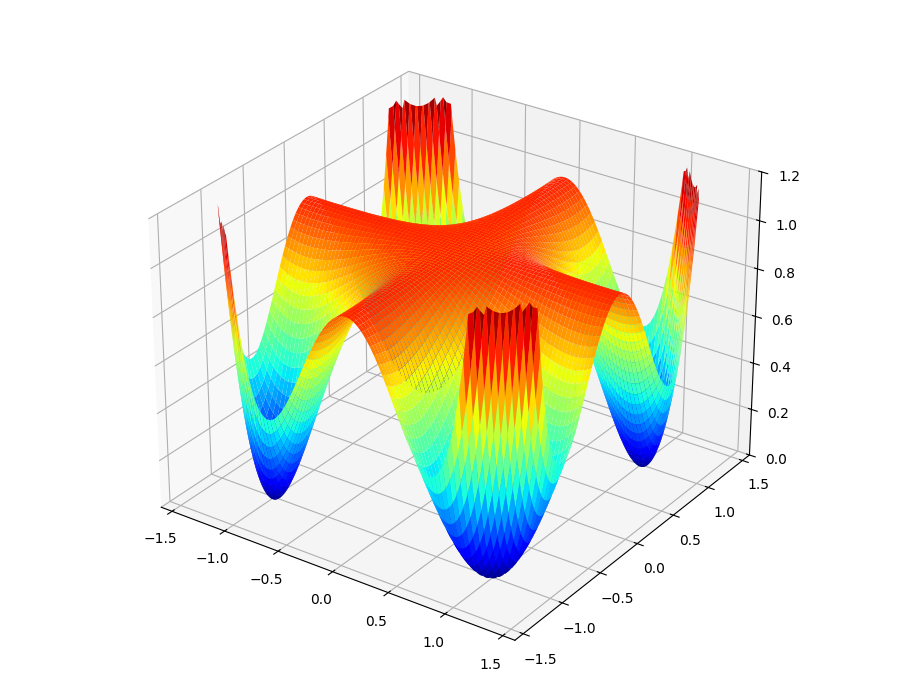
Even though Hilbert proved that the equality holds only in some special cases, the first explicit counterexample was considered much later by Motzkin in 1967:
When plotted as a function on its surface looks like this:
Proving that it is globally non-negative is a simple application of the AM-GM inequality:
Rearranging yields . The next result is the key to algorithmically deciding whether a given polynomial is sos.
Proposition (Parameterization of ): Let be a monomial basis of the truncated polynomial ring written as column vector. A polynomial is sos if and only if there exists a psd matrix such that
The exact choice of basis does not matter of course. This matrix will be refered to as the Gram matrix.
Proof: If there exists such a we may proceed as in the quadratic polynomial case above: using a Cholesky factorization and plugging this in yields a sum-of-squares expression . Conversely, if is sos, we may write each (which is necessarily of degree at most ) in terms of the basis: . Thus, and by summing these up we get . Finally, we observe that is psd as a sum of rank-1 psd matrices.
Checking whether the Motzkin polynomial (or any polynomial for that matter) is sos is therefore equivalent to checking whether the linear system
obtained via coefficient matching has a psd solution .
In other words, it is equivalent to checking whether the intersection of an affine subspace
with the convex cone of psd matrices is non-empty.
A problem of this type can be solved in practice by
semidefinite programming
(short, sdp) solvers.
The experiment motzkin_not_sos.py computes exactly this - see the first of the two tests.
(.venv) $ motzkin-not-sos
Starting test: Is M(x,y) a sum of squares? ... Computation finished.
Solution status: infeasible
Solve time: 0.00112448s
Iterations: 9
Starting test: Is (x^2 + y^2) * M(x,y) a sum of squares? ... Computation finished.
Solution status: optimal
Solve time: 0.005551222s
Iterations: 12
This tells us that the the decomposition failed and that the Motzkin polynomial is not sos. Some implementations of the so-called interior point method will also return a "dual infeasibility certificate": To understand what that means exactly we need to study the conic dual of . For now it is enough to think about such certificates as a concrete hyperplane in some closely related cone that separates the compact feasible region from the point of interest. More on this later.
So Motzkin is now verfiably not sos. However, according to the second test that is performed in the experiment, it turns out that the product of Motzkin with some other sos polynomial results in something sos. This is not just a coincidence. Hilbert's result from the last section motivated a new question (which became Problem 17): Is every non-negative polynomial a sum of squares of rational functions? This has been answered positively by (Artin, 1927). In our case, is not sos, but it is fraction of two sos polynomials: the denominator is and the numerator was provided by the Gram matrix , which was computed by the sdp solver.
In fact, one does not even have to guess the denominator as we did here.
The documentation of the Julia package SumsOfSquares.jl demonstrates how to build a program that not only
searches the decomposition of the product but also the denominator in one run given some
upper bound on the degree.
Let's rephrase this:
Any polynomial inequality can - in principle - be automatically proven or disproven
by means of semidefinite programming.
If it is true, then the sdp solver will provide a proof in the shape of a Gram matrix,
which is equivalent to an explicit sos decomposition, which in turn, proves non-negativity.
On the other hand, if the inequality is false, then the solver may return an infeasibility
certificate as we have seen before.
As powerful as this sounds, there are two important caveats. For one, it is always important to be aware of possible issues with accuracy since interior point methods are implemented using numerical linear algebra routines. Moreover, the dimensions of such sdps explode very quickly if constructed naively. The monomial vector , for instance, will have length , and an interior point solver itself will have rather high runtime costs being a second-order method working on large matrices. The research communities around these methods have found various tricks to circumvent cost or trade it off with accuracy (e.g. by exploiting more structure of problem instances or using more specialized solvers).
In this section we will localize the non-negativity to sets described by polynomial inequalities and formulate a effective procedure for solving optimization problems over them.
Let be arbitrary polynomials and let them define the basic semialgebraic set
Such sets may take a wide variety of shapes. Here are just a few basic compact examples:
Note that this last example illustrates how to achieve equality constaints as well: simply add the negative of the polynomial to the mix. We will assume throughout that is compact.
Next, consider a polynomial objective function and consider the polynomial optimization problem (or pop for short)
Problems of this rather innocent looking form encode a large variety of problems appearing in practice: for starters, note that this already includes the whole classes of linear and quadratically constrained programming (themselves classes of broad application) as well as that of non-linear programming in binary variables which is of high interest to the field of combinatorial optimization. Researchers have applied the method we are going to discuss in domains like power systems design, dynamical systems analysis, quantum information theory and to find sharp approximations to many famous NP-hard problems like MaxCut or StableSet.
While pops are hard, non-convex problems in general, we can reformulate them into a convex problem (albeit an infinite dimensional one) by using the language of non-negativity. Define the new convex cone (exercise: verify that this is really a convex cone). With it, reformulate
Indeed, let be a minimizer in the first formulation (remember: was assumed to be compact) and be the maximizer of the second formulation. Then, the polynomial is non-negative on . If were strictly positive on , it would contradict the optimality of , and therefore .
How lucky for us, that we already know very well how to relax non-negativity - let's go back to sums of squares.
Definition: The quadratic module associated to the polynomials is defined as
For a given degree we also define the truncated quadratic module
The purpose is clear: any is non-negative on since on for all . Thus, similar to how relaxes , the new convex cone relaxes .
Note that membership in the truncated quadratic module will only certify non-negativity on if all of the summands appear. The truncation degree must be chosen to be greater or equal .
Moreover, observe that we declared explicit dependence on the defining inequalities instead of itself. Different descriptions may result in different quadratic modules, but we can only write down an effective certificate if we know a description.
Now we are ready to define the sums-of-squares hierarchy:
These define a sequence of convex, finite-dimensional optimization problems. As we increase the hierarchy level , the search space grows and we find ourselves in a chain of inequalities
The first immediate question is: will this converge? That is, will as ? Lucky us again:
Theorem (Putinar's Positivstellensatz, 1993): Assume that is compact and the quadratic module is Archimedean, i.e. if for some . If , then for all .
The word Positivstellensatz was chosen in analogy to the German Nullstellensatz in algebraic geometry. A constructive and elementary proof of this result can be found in (Schweighofer, 2005).
Let us first have a look at the Archimedean condition, which is a technical assumption only and closely related to the discussion above: the quadratic module depends on the description of the set and not the set itself. All it says is that you need to have such a ball constraint in the module for guaranteed convergence. Practically, this is not a deal-breaker. If you already know (maybe approximately) diameter and location of , or if you have an a-priori bound on where the minimizers should be, it is enough to add this inequality without changing anything.
So how does this help us? Think of as the sharpness of the bound. For any desired sharpness, Putinar tells us that we will be able to decompose a polynomial into the form required for membership in the quadratic module as long as we are willing to wiggle by . Therefore, as we go up in hierarchy level, i.e. in truncation degree, we will be able to tighten our bounds, i.e. to let , because we gradually enlarge the search space. This proves asymptotic convergence of the sos hierarchy.
Since we did not leave the framework of the last section, we are again able to use semidefinite programming to solve such optimization problems. Let's take again the Motzkin polynomial from the previous section and try to minimize it on a non-centered ball. In other words, we attempt to solve the problem of maximizing a scalar such that the linear coefficient matching system
is satisfied and such that the the two polynomials and are sos, i.e. can be described by two psd matrix variables.
Before, we were dealing only with feasibility and now we also need to optimize a linear function at the same time.
Also, note that the first hierarchy level that makes sense here is - anything below and the coefficient matching system would be over-determined.
This problem is implemented in the experiment motzkin_minimize.py; check out the code to see how to hand these data to a solver.
Here is the result:
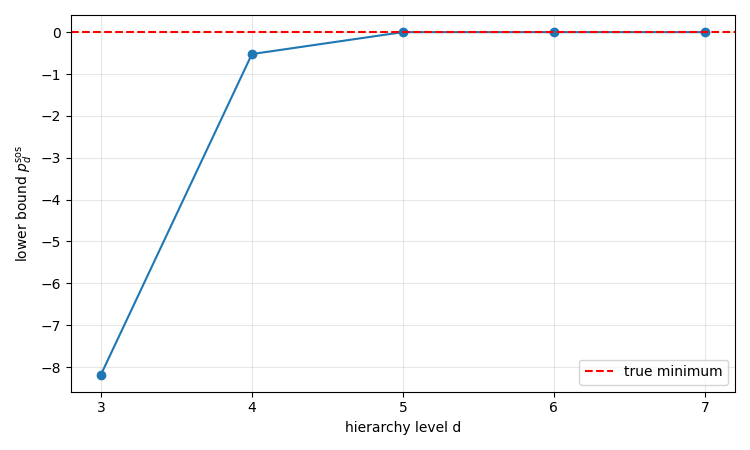
This is converging to the minimum (or rather to numerical precision) quite fast. Is the Archimedean condition satisfied here?
As so often in mathematics, taking a closer look at the dual of a given problem/concept/space/... can be very fruitful. In this section we are going to examine exactly the same problem, i.e. the polynomial optimization problem
for the compact semialgebraic set but we choose a different road to arrive at the hierarchies of lower bounds. This will lead us naturally to the dual theory of moments.
Consider the following reformulation: Let us denote by the convex (!) set of all probability measures supported on (all mass lies inside or equivalently the measure of is zero for any ). Then,
At first glance, this might seem a bit strange but let us quickly verify that this is in fact true:
The language that we are going to use for these two last sections will be introduced now for yet another reformulation of this integral expression.
Definition: The moment cone is the set of all linear functionals on the polynomial ring for which there is a measure such that
Similarly, for a set we define the localized moment cone as the set of all linear functions on that are integration w.r.t. a measure supported on .
Note that we did not require these measures to be probability measures. The reason is that would fail to be a cone if we did (verify this for yourself!). That said, if is such a functional then requiring it to be integration w.r.t. to some probability measure is as simple as enforcing .
In this notation, we may write
We present now the key theorem that establishes duality. Let us denote the dual of a vector space by . If is any cone inside then we define the dual cone as .
Theorem (Haviland, 1936): If is a closed subset, then the moment is the dual of the cone of non-negative polynomials, i.e.
Functionals that preserve positivity like this one are sometimes called positive functionals. One direction is quite simple: if is integration w.r.t. to some measure, then one verifies immediately that non-negative polynomials map to non-negative values. The other direction is a bit more involved; here is the outline: First, extend to positive functionals on the space of smooth functions that grow at most polynomially. There, apply the measure-theoretic variant of Riesz' representation theorem for the space of compactly supported functions (as presented for instance in (Folland, 1999)) to assert the existence of a measure. Lastly, show that the representation still holds for smooth polynomially growing functions - in particular for polynomials themselves. The detailed proof can be found in Section 4.6 of (Laurent, 2010). Note also that the assumption is that is merely closed. For our purposes it would be enough to show the theorem in the compact case.
Now, that we have established duality with the cone of non-negative polynomials, we also realize that testing membership is at least as hard as for . We will therefore introduce a relaxation as the dual to the sums of squares cone and quadratic modules:
Definition: The pseudo-moment cone is defined as the conic dual to , i.e.
Analogously, for polynomials defining a basic semialgebraic set we define the localized pseudo-moment cone as
The prefix "pseudo" is justified: while the sos cone was an inner approximation, we are now in the situation of an outer approximation , i.e. not all pseudo-moments come from a measure. Indeed, being positive on all sos polynomials is a more inclusive condition than being non-negative. Moreover, as we will detail in the next section, membership is again tractable in the sense of semidefinite programming.
As before, we now have all the ingredients together to define the dual lower bound on :
This is a lower bound simply because we enlarge the feasible set.
Warning: Both the inner approximation in the sos case and the outer approximation in the moment case led to lower bounds. Keep in mind that the former used a little trick which transformed the problem into maximization, while the moment side stayed a minimization problem. For this reason, the sos side is usually referred to in the literature as the dual and the moment side as the primal - this is somewhat opposite to the flow of this introduction to the Moment-SOS hierarchy. Have a look at one of the original expositions in to verify this yourself.
We may also introduce the respective truncated (pseudo-)moment cones , , and in the expected way: Instead of considering functionals on the whole polynomial ring, we only look at . This leads then to the (completely analogous) hierarchy of finite-dimensional convex optimization problems
with the chain of inequalities . It should not come as a surprise now that both bounds and are tightly linked:
Proposition (Weak duality): For large enough (for the optimization problem to be well-defined) we have and .
Proof: Let be a feasible solution for the optimization problem : there exists some such that . If is any feasible solution for the optimization problem (i.e. is non-negative on the quadratic module generated by ), then in particular
Thus, . Because the feasible solutions from both problems were arbitrary, the inequality holds for the optima due to closedness.
Under certain conditions, often encountered in practice, the two problems are also strongly dual (i.e. ). One such sufficient condition is that the semialgebraic set has non-empty interior (see Theorem 6.1 in (Laurent, 2010)).
The weak duality result has a strong consequence: Recall that Putinar's Positivstellensatz established that in case of compact with Archimedean description. Since , it also shows asymptotic convergence of the moment hierarchy in that case.
The purpose of this final section is to show how to pass the data of the moment relaxation at some degree truncation to a solver. Afterwards, we answer an important question: how can we possibly know at which degree we can stop going up in the hierarchy? Under such circumstances it will also be possible to use the solver outputs to extract concrete minimizers.
First, let us show that the levels of the moment hierarchy are again semidefinite programs. In the following proposition we may easily replace the infinite localized pseudo-moment cone by a truncation with the same result.
Proposition: Extend the description of the semialgebraic set by the constant polynomial (this does not change the set as trivially ). To a linear functional and for each we associate the bilinear form
Then, a functional is a member of the localized pseudo-moment cone if and only if all associated bilinear forms are psd ().
This is the analogon to the positive semidefinite description of the sos cone and of the truncated module.
Proof: If then it is non-negative on the truncated module. In particular, it is non-negative on each polynomial of the form (choose the zero polynomial for all other terms of a generic member of the quadratic module). But then for any polynomial , so is psd. Conversely, let be a linear functional such that all bilinear forms are psd. Let be an arbitrary element of the quadratic module. Thus,
so is a localized pseudo-moment functional.
Let us now pass to the truncated case. Here, of course we would like to talk about concrete matrices instead of bilinear forms or functionals so that we can pass them numerically to a solver. We will need to choose a basis. For simplicity, and because it is standard we will again choose the monomial basis truncated at some degree . For the polynomial ring in variables , the (unsorted) monomial basis in multi-index notation is
Note that any functional on the truncated polynomial ring evaluated at a polynomial can be expressed as
where is the corresponding coefficient of and is now a vector of size equal to that of the basis. In the last expression, we simply interpret as a vector in the monomial basis as a shorthand notation. Thus, we will from now on speak about (pseudo-)moment vectors instead of (pseudo-)moment functionals .
In the literature the following notation for the matrices of bilinear forms from the last proposition is very common. Starting with , i.e. for the trivial addition , the moment matrix corresponding to the bilinear form associated to is defined as the matrix with entries indexed by multi-indices
This might seem a bit strange at first glance; it's always good to see an example. Let's consider the case and . Let be a moment vector with one entry for each monomial in two variables up to degree . Then, the associated moment matrix is
Note that you can find for as the upper left -submatrix. It's a good exercise to write out a moment matrix like this for yourself (e.g. try the case and ).
For , we need to shift and add monomials according to the vector . For multi-indices we define the localizing (moment) matrix
As an example, let us consider a centered ball constraint (those that are required by Putinar's theorem) with and , so . Under this setup the localizing matrix is
This is exactly the moment matrix in which each entry is scaled and shifted by the coefficients and exponents of the constaint.
In this new matrix notation we can reformulate into a version that can be passed to solvers. Let's make this a bit more explicit than previously to figure out which degrees we really need (compare to the degree constraints on the individual terms of the quadratic module). Write
to denote the rounded up half-degrees of all polynomials that define the semialgebraic set . Then, the minimum degree for a moment (or sos) relaxation to make sense will denoted by Then, for any hierarchy level and letting , we arrive at our final formulation
where we used the shorthand for a matrix to be psd.
Note that .
This is now precise enough to be passed to a solver.
Check out the first part of the code for the experiment motzkin_moment.py to see this in action.
We finish this introduction with a short discussion of the question: at which degree can I stop going up in the hierarchy? When have I reached the optimum? This is a very relevant question as the dimension of (and with it the size of our moment matrices) grow rapidly leading to numerical difficulty. See Sections 6.6 and 6.7 in (Laurent, 2010)) for a detailed discussion.
Here is a first simple criterion. Denote by the multi-indices corresponding to the monomials .
Proposition: Let be an optimal solution for the problem . Define . If and , then and is a minimizer to the original problem, i.e. .
Here is some intuition for this result. If were given by integration w.r.t. a probability measure , then one could think of as being concentrated tightly around a true minimizer (close to a Dirac at that point), so that the moments are large only if and only if is close to the true -th coordinate of the minimizer.
Proof: Since , we certainly have . But by assumption we also have since the hierarchy produces lower bounds.
While this is generally a rare situation to be in, there are heuristic arguments to be made that this has a good chance of being true in case of a unique global minimizer to the original problem (cf. the sections of the survey mentioned above).
We perform this test in the experiment
motzkin_moment.py.
As before we attempt to minimize the Motzkin polynomial around a small ball around one of the minimal points at with value .
At each hierarchy level we log the found lower bound and check numerically if the criteria for the last proposition are satisfied.
Here is the result on my system:
$ motzkin-moment
hierarchy level d = 6
-> solver status: optimal
-> pmom_6 = -1.0611336720423026e-06
-> xbar = [0.9300696568198683, -0.923372680505846]
-> constraint value g1(xbar): 0.0507619989901501 (feasible)
-> |p(xbar) - pmom_6| = 0.05421546272582045
hierarchy level d = 7
-> solver status: optimal
-> pmom_7 = 1.7405777708034975e-08
-> xbar = [0.9193142154224452, -0.9144839411955861]
-> constraint value g1(xbar): 0.053823192146335685 (feasible)
-> |p(xbar) - pmom_7| = 0.0680625302440645
hierarchy level d = 8
-> solver status: optimal
-> pmom_8 = 2.7041787764581215e-07
-> xbar = [0.9400211494212625, -0.9412264389430985]
-> constraint value g1(xbar): 0.04705179399605586 (feasible)
-> |p(xbar) - pmom_8| = 0.03677300078418422
hierarchy level d = 9
-> solver status: optimal
-> pmom_9 = 3.097746410496427e-07
-> xbar = [0.9636166109044235, -0.9623476028476482]
-> constraint value g1(xbar): 0.04274145401339868 (feasible)
-> |p(xbar) - pmom_9| = 0.015074659455620143
hierarchy level d = 10
-> solver status: optimal
-> pmom_10 = 1.2811140037705115e-07
-> xbar = [0.9690466266312561, -0.9692733473958901]
-> constraint value g1(xbar): 0.04190223850315855 (feasible)
-> |p(xbar) - pmom_10| = 0.010615989938524306
hierarchy level d = 11
-> solver status: optimal
-> pmom_11 = 3.0463441458294938e-06
-> xbar = [0.8830502005680481, -0.8842745049144566]
-> constraint value g1(xbar): 0.06706964579996799 (feasible)
-> |p(xbar) - pmom_11| = 0.12301890909944158
hierarchy level d = 12
-> solver status: optimal
-> pmom_12 = 8.13755707262942e-07
-> xbar = [0.956053920985409, -0.9587413539555535]
-> constraint value g1(xbar): 0.043633533734177554 (feasible)
-> |p(xbar) - pmom_12| = 0.019707880115166
hierarchy level d = 13
-> solver status: optimal
-> pmom_13 = 8.671382947245121e-07
-> xbar = [0.97056788804639, -0.9704954375080612]
-> constraint value g1(xbar): 0.04173676842189067 (feasible)
-> |p(xbar) - pmom_13| = 0.009723313378852128
As it turns out, we do indeed approach the true (and unique!) minimizer but we do so very, very slowly. Note that although the lower bound already hits numerical precision, we cannot apply the result yet. Intuitively, increasing the hierarchy level brings the pseudo-moment vector closer to the true infinite moment vector of the optimal measure, but we need a lot more information to produce minimizers than to get tight lower bounds.
There is a more general theorem which includes this strategy as a special case and but with broader applicability. Loosely speaking, one is able to extract minimizers if the sequence of ranks of the moment matrices in the hierarchy level stabilizes.
Theorem (Rank stabilization): Let be the maximum rounded up half-degree of the polynomials that define . For let be an optimal solution to . Assume that there is some with for which
In this case, the associated functional is integration w.r.t. an -atomic probability measure
which is convex combination of Dirac deltas. Moreover, the points are global minimizers to the pop, i.e. .
Without going into detail, it is possible to extract the minimizers from such a setting by means of numerical linear algebra.
These results highlight the advantages of considering both the sos and the moment side of the hierarchy: We've seen that the sos side gives us algebraic proofs for a given bound by producing an explicit element of the quadratic module. The moment side on the other hand is closer in nature to distributions on the set itself and as such might give us access to stopping criteria and concrete minimizers.